Analysis
Introduction
This section dig into the world of basic principles. Sometimes the discussed topic is far behind the "basics lecture notes" but anyway: it is a nice area with a lot of interesting details. Concern the term "basic" as background knowledge.
The first section start with the basic design of hash functions. The second section elucidated some background knowledge about Pseudorandom Number Generators (PRNG).
Avalanche
One key indicator of a hash function is the ability to spread message bits throughout all bits of the resultset. The avalanche behaviour states that any single bit change in the input keys will on average flip half the bits in the output. The following figure demonstrate the effect if one bit toggles. The smaller arrows points to bit flips in the input and output vector (one changed input bit, four changed output bits):
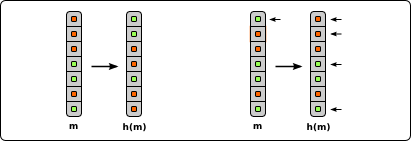 One note: the input as well as the output is 7bit width (upright in the previous figure) the avalanche behaviour
is in the figure 0.571429. Therefore 0 means no effect at all and 1 means change
all output bits completly. 0.5 is the ambition! ;-)
But the avalanche behaviour concentrate on the average situation - one pass like in the figure
is next to nothing!
This charactersitic of a hash function is important because keys tend to be "similar". For example,
think about your natural language! First, in English there 7bit are sufficient - the 8 bit is 0. Then on the
other side think about the frequency of letters. In German E has a relativ occurrence of 17,40 %, N
9,78 % and so on. But that's not the only relations: The most common initial letter in German is D with
14,2 % followed by S with 10,8 %.
Words are often keys, but that no mandatory regulation. Often keys are symbols. Think about the situation when you
use a library (e.g. glibc) that resolves the function names (e.g. getline(3)). The names are saved within a
hashtable in the ELF file. Now think about your programm, ... are there are similar patterns to note? For example
underscores at the begining.
Type readelf -s PATHTOPROGRAM | awk '{print $8}'. This will list all symbols in the object file, local and
global ones.
Anyway: a good hash function should calculate good results for every type of key! If thats not
true for your hashfunction than this is an idicator for other waek spots too!
The following four figures demostrate the avalanche behaviour of four well-known functions,
Goulburn, Hsieh, Phong and Korzendorfer1 (from left to right and top to bottom).
One note: the input as well as the output is 7bit width (upright in the previous figure) the avalanche behaviour
is in the figure 0.571429. Therefore 0 means no effect at all and 1 means change
all output bits completly. 0.5 is the ambition! ;-)
But the avalanche behaviour concentrate on the average situation - one pass like in the figure
is next to nothing!
This charactersitic of a hash function is important because keys tend to be "similar". For example,
think about your natural language! First, in English there 7bit are sufficient - the 8 bit is 0. Then on the
other side think about the frequency of letters. In German E has a relativ occurrence of 17,40 %, N
9,78 % and so on. But that's not the only relations: The most common initial letter in German is D with
14,2 % followed by S with 10,8 %.
Words are often keys, but that no mandatory regulation. Often keys are symbols. Think about the situation when you
use a library (e.g. glibc) that resolves the function names (e.g. getline(3)). The names are saved within a
hashtable in the ELF file. Now think about your programm, ... are there are similar patterns to note? For example
underscores at the begining.
Type readelf -s PATHTOPROGRAM | awk '{print $8}'. This will list all symbols in the object file, local and
global ones.
Anyway: a good hash function should calculate good results for every type of key! If thats not
true for your hashfunction than this is an idicator for other waek spots too!
The following four figures demostrate the avalanche behaviour of four well-known functions,
Goulburn, Hsieh, Phong and Korzendorfer1 (from left to right and top to bottom).
Note: not all figures are scaled in the Z axis from 0 to 10. (0: no effect, 5 perfect and 10 all bits touched).
 |
 |
 |
 |
Timing Impact
The following figure show the timing impact for different hash functions and variable input size hashkeys.